
Как создавался кластеризатор
14 февраля 2017 вышла статья «Excel-кластеризатор ключевых слов по весу». Я описал метод группировки ключевых слов для контекстной рекламы и показал как всё сделать в Excel. И получил полсотни вопросов «Как появилась такая последовательность действий?».
Об этом и хочу рассказать: как создавался кластеризатор, какие были проблемы и как решал.
Идея
До IT-Agency я работал с небольшими рекламными кампаниями, максимум 500 ключевых слов. Группировку делал вручную и этого было достаточно.
При первом же столкновении с кампанией на 2—3 тысячи ключевых слов захотелось сократить ручную работу. Пробовал несколько онлайн кластеризаторов — результат мне не понравился. Плюс я не понимал как он получился и не мог на него влиять.
Но задачу надо сделать и сделать качественно. Поэтому открыл Excel и начал работу.
Этапы
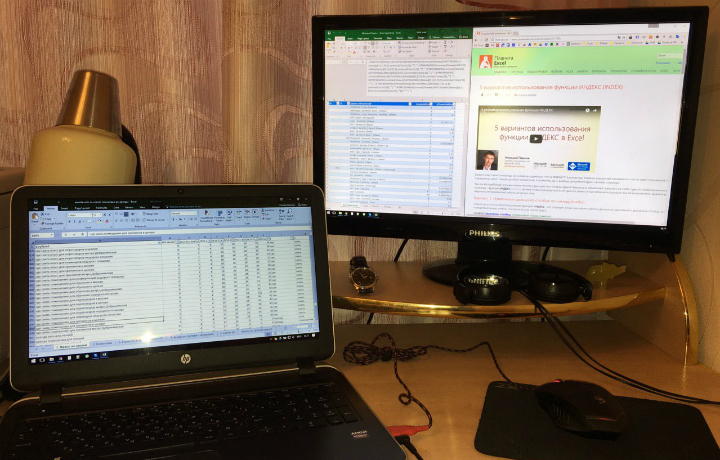
Первая идея — использовать стандартный фильтр Excel. Я фильтровал список фраз используя 15—20 слов, которые чаще всего встречались. Каждый раз, при фильтрации, я указывал в соседних столбцах слова, которые были условием для фильтра. Перебрав все основные слова склеивал их CONCATENATE-ом в название группы.
Это немного ускоряло процесс на СЯ до 1000 фраз, а на более крупных списках наоборот, замедляло. Слова для фильтра я выбирал по наитию — надо было найти способ выделять действительно важные слова.
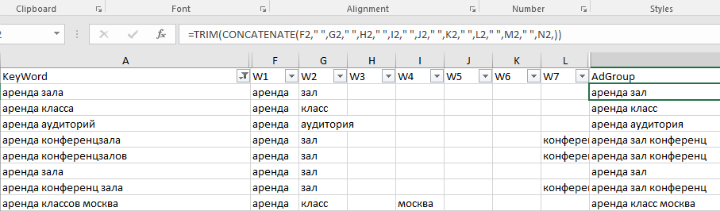
Так появился второй этап и «развесовка» — составление упорядоченного по важности справочника слов. Я решил разбить все фразы по словам и посчитать их вес — частотность фразы делённая на кол-во слов во фразе. Забавно, но про функцию «text to columns» я не знал. Чтобы разбить фразы по словам вычислял позицию каждого пробела и с помощью функций LEFT, RIGHT, MID вытягивал нужное слово.
Сразу всплыла новая проблема: одно и то же слово может быть с разными окончаниями. Их можно сгруппировать по общей части — корню. Добавил формирование таблицы-справочника с корнями слов: копировал столбцы со словами → объединял в таблицу → убивал дубли → прописывал вручную корень для каждого слова. Это занимало супер-много времени.
Сортировка по прежнему была ручной — напротив каждой фразы надо было проставить список слов, из которых собиралось название группы объявлений. Я не знал сколько слов использовать для сортировки — просто брал 15—20 самых «важных». При этом, таблица начала оформлятся в некий инструмент и я загорелся довести её до ума.
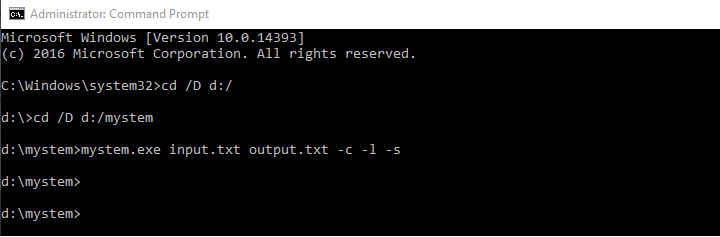
Третий этап появился, когда я узнал про mystem — вжух и минус пара часов на формирование справочника с корнями. Теперь это справочник с леммами.
Кроме mystem, на третьем этапе добавились «умные таблицы» и стандартизированные формулы — время обработки списка фраз значительно сократилось и я решил продавать идею ребятам в агентстве.
Собрал фидбэк: «важность» рассчитывается стрёмно и необъективно, прописывать руками слова для формирования названия группы объявлений — ад. Ок, зато честно и по делу. Так начался четвёртый этап.
Чтобы сделать «важность» более объективной добавил в формулу кол-во упоминаний и переработал механизм формирования справочников слов и лемм: оставил дубли слов и использую их при расчете кол-ва упоминаний леммы.
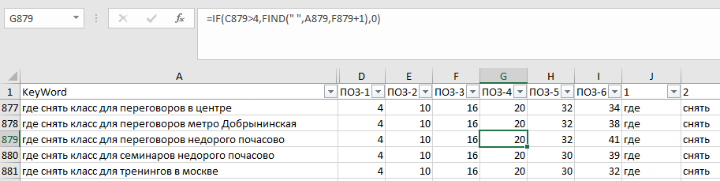
Задача автоматизировать формирование названия группы объявлений была самой сложной и интересной. Для её решения отлично подошел метод перебора. Чтобы всё работало в справочник лемм добавил порядковые номера (теперь называю это «статусом» — выполняет несколько функций), а в общую таблицу добавил столбцы со статусами и написал формулу формирования названия группы объявлений:
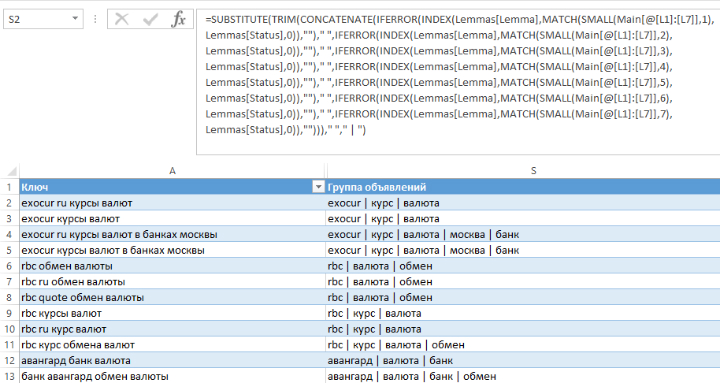
Самое главное в формуле — функция SMALL. Она возвращает определенное по счету наименьшее значение. Последовательность функций SMALL сортирует диапазон: 700-100-37-200 превращаем в 37-100-200-700. Связка INDEX & MATCH заменяет VLOOKUP, TRIM убирает лишние пробелы, а CONCATENATE собирает всё в кучу.
Вот так за четыре этапа появился Кластеризатор. На это ушло 8 месяцев. На каждом этапе удавалось сортировать всё больше фраз. Остановился на 45 000 — Excel уже не справляется. Сейчас разбираюсь с Power Query и Data Model чтобы снять это ограничение. Продолжение следует!
Спасибо за статью и кластеризатор
Обратите внимание на программу Key Collector
В ней есть возможность автоматически сгруппировать ключевые слова, и отсортировать группы по кол-ву фраз в каждой группе или по суммарной частотности ключевых слов в группе:
http://www.key-collector.ru/datagrids.php#stemmed_tool
Сам пользуюсь постоянно, экономит время и позволяет выполнять различные задачи, не только по кластеризации
Добрый день, Эдуард!
Спасибо, про KeyCollector знаю и пользуюсь регулярно — собираю семантику. Даже антикапчу купил ;).
Встроенной группировкой пользовался пару раз — результат не очень понравился и разбираться дальше не стал. Мне важно понимать как получается результат и как на него влиять. Поэтому решил сделать свой инструмент. Это не универсальная панацея, но мне экономит очень много времени. Плюс, всегда можно добавить что-нибудь.